Gen Code & Data Pipeline
The driver of the operation. During SFT, it generates synthetic trajectories for data curation. In RL, it executes policy-based actions. For Evaluation, it runs benchmark tasks against the environment.
A universal execution layer powering the complete model lifecycle:
Data Curation (SFT), Reinforcement Learning (RL), and Benchmark Evaluation.
This infrastructure provides the "ground truth" for model development. By running tasks in real Windows containers, we support the entire pipeline from initial data synthesis to final benchmarking.
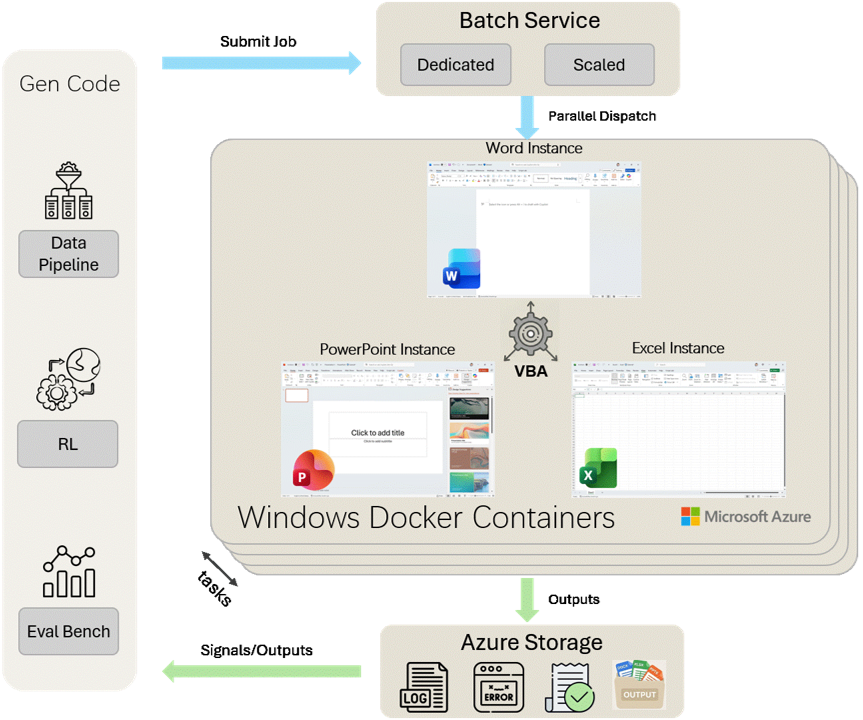
Breakdown of the operational modules in the diagram.
The driver of the operation. During SFT, it generates synthetic trajectories for data curation. In RL, it executes policy-based actions. For Evaluation, it runs benchmark tasks against the environment.
Leverages Azure Batch to handle massive parallelism across all lifecycle stages. It dynamically scales resources whether running a nightly benchmark or a week-long RL training run.
Architecture Highlight: These containers run full Windows environments. This allows the system to verify visual outcomes (e.g., "is the text bold?") which is critical for both Reward calculation and Benchmark scoring.
Azure Storage captures the results. It records successful trajectories for training data, calculates reward signals for the RL policy, and stores output documents for performance analysis.
The technical foundation powering the containers.